
Author | Chen Chen
Produced by | NetEase Tech

The first official keynote of CES 2026 belonged to AMD CEO Dr. Lisa Su. Amidst a packed house of anticipation, she formally unveiled AMD's "AI Everywhere" strategic vision: facing the challenge of computing demand surging 100-fold in the next five years, AMD is committed to extending AI from cloud data centers to every corner of the physical world.
During the hardware showcase, Su revealed the next-generation AI data center rack Helios and the flagship processor MI455X on stage, and disclosed an industry-notable roadmap: the highly anticipated 2nm process MI500 series chips will launch in 2027.
Midway through the keynote, OpenAI President Greg Brockman was invited on stage, stating bluntly that the demand for computing power is "almost limitless," directly affirming that AMD is already a core computing pillar supporting ChatGPT and the evolution of future models.
The "Physical AI" demonstration in the latter part was visually stunning: Fei-Fei Li demonstrated the "Marble" model constructing a realistic Hobbit world from scratch; Generative Bionics CEO brought the humanoid robot Gene 1 onto the stage and announced mass production would begin in the second half of 2026. From cloud to edge, this marks AMD's technology ecosystem accelerating its penetration into real-world physical interactions.
Below is the transcript of Lisa Su's CES 2026 keynote (edited and slightly modified, subtitles added later):
1. Opening Remarks
The Moment AI Changes the World
Lisa Su: First, thank you to the host, and welcome to everyone here in Las Vegas and participating online. It's great to kick off CES 2026 with all of you.
I have to say, I love coming to CES every year to see all the latest and greatest tech and catch up with so many friends and partners. But this year, I'm especially honored to help kick things off with all of you.
We have a packed show for you tonight, and the theme tonight, without a doubt, is AI.
Even though the pace and speed of AI innovation over the last few years has been incredible, my theme for tonight is: You ain't seen nothing yet.
We're just beginning to realize the power of AI. Tonight, I'm going to show you a range of where we're going next. I'm also going to bring some of the world's top experts on stage, from industry giants to breakthrough startups. Together, we're going to make AI everywhere, for everyone. So, let's get started.
At AMD, our mission is to push the boundaries of high-performance and AI computing to help solve the world's most important challenges. Today, I'm incredibly proud to say that AMD technology touches billions of lives every day. From the largest cloud data centers to the world's fastest supercomputers, to 5G networks, transportation, and gaming, every one of these areas is being reshaped by AI.
AI is the most important technology in the last 50 years, and I can say with certainty, it is absolutely AMD's number one priority.
It's already touching every major industry. Whether you're talking about healthcare, science, manufacturing, or business, and that's just the tip of the iceberg. AI will be everywhere in the coming years. Most importantly, AI is for everyone. It makes us smarter, it makes us more capable. It lets each of us be a more efficient version of ourselves.
At AMD, we're building the computing foundation to make that future a reality for every company and every person.
Since ChatGPT launched a few years ago, I'm sure you all remember the first time you tried it. We've gone from a million people using AI to over a billion active users today. That's incredible growth. It took the internet decades to reach the same milestone.
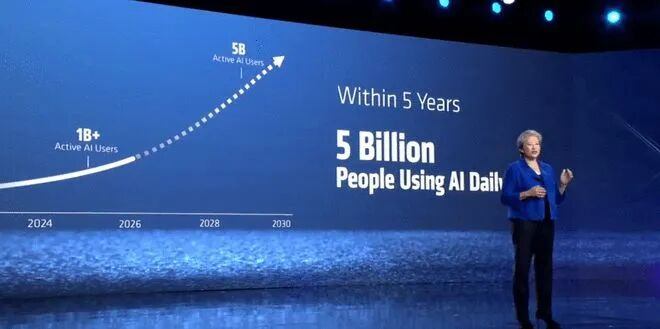
And our projections now are even more incredible. We see AI adoption growing to over five billion active users, as AI becomes as integral to our lives as phones and the internet are today.
The foundation of AI is compute.
As users grow, we see global compute infrastructure demand skyrocketing, from about 1 Zettaflop in 2022 to over 100 Zettaflops in 2025.
Sounds big. That's actually 100x growth in just a few years. But what you'll hear from our guests tonight is that we don't have nearly enough compute for everything we can do. Incredible innovation is happening. Models are getting more capable. They're thinking and reasoning. They're making better decisions. And that trend goes even further as we scale to broader agents.
So, to make AI everywhere, we need to increase global compute another 100x in the coming years, to over 10 Yottaflops in the next five years.
Let me do a survey. How many of you know what a Yottaflop is? Raise your hands.
1 Yottaflop is a 1 with 24 zeros. So 10 Yottaflops is 10,000x the compute we had in 2022.
Nothing like this has ever happened in the history of computing. And it's entirely because there's never been a technology like AI.
To get there, we need AI in every compute platform. So what we're going to talk about tonight is the full spectrum. We're going to talk about the cloud, where AI runs continuously and delivers intelligence globally. We'll talk about the PC, where AI helps us work smarter and personalize every experience. And we'll talk about the edge, where AI powers machines making real-time decisions in the physical world.
AMD is the only company with the full spectrum of compute engines to make this vision happen. You need the right compute engine for every workload. That means GPUs, CPUs, NPUs, and custom accelerators. We have it all. Each can be tuned for the application, giving you the best performance and the most cost-effective solution.
Tonight, we're going to take a journey. You'll go through a few chapters with me, showing the latest AI innovations in the cloud, the PC, healthcare, and more.
2. Cloud AI & The Helios Platform
Let's start with chapter one: the cloud.
The cloud is where the largest models are trained, and where intelligence is delivered in real-time to billions of users. For developers, the cloud gives them instant access to massive compute, the latest tools, and the ability to deploy and scale as use cases explode. The cloud is also where most of us experience AI today. Whether you're using ChatGPT, Gemini, or Grok, or using Copilot to write code, all those powerful models run in the cloud.
Today, AMD is powering AI at every layer of the cloud. Every major cloud provider runs AMD EPYC CPUs, eight of the top ten AI companies use Instinct accelerators to power their most advanced models, and the demand for compute just keeps going up. Let me show you a couple of charts.
Over the last decade, the compute needed to train leading AI models has grown more than 4x every year. That trend continues. That's why we have smarter, more useful models today.
At the same time, as more people use AI, we've seen inference explode over the last two years, with tokens growing 100x, truly hitting an inflection point. You can see inference demand taking off. To meet that compute demand, it really takes the entire ecosystem coming together.
So we often say the real challenge is how to deploy AI infrastructure at Yotta-scale, and that takes more than just raw performance.
It starts with leading compute—the combination of CPUs, GPUs, and networking technology. It takes an open, modular rack design that can evolve across product generations.
It takes high-speed networking to connect thousands of accelerators into a single, unified system. And it has to be incredibly easy to deploy. So we need a full-stack solution.

That's exactly why we built Helios, our next-generation rack-scale platform for the Yotta-scale AI era.
Helios takes innovation at every level—hardware, software, and systems. It starts with our next-generation Instinct MI455 accelerator, designed by our engineering teams, delivering our largest generational performance leap ever.
The MI455 GPU is built with leading 2nm and 3nm process technology, combined with advanced 3D Chiplet packaging and ultra-fast, high-bandwidth HBM4 memory.
These are integrated into compute trays, paired with our EPYC CPUs and Pensando networking chips, creating a tightly integrated platform.
Each tray is connected via a high-speed Ultra Accelerator Link protocol based on Ethernet tunneling, enabling 72 GPUs in a rack to operate as a single compute unit. On top of that, we can connect thousands of Helios racks, building powerful AI clusters with industry-standard Ultra Ethernet NICs and Pensando programmable DPUs, further accelerating AI performance by offloading tasks from the GPU.
Since we're at CES, we have to have a show. I'm proud to show you Helios—the world's best AI rack—right here in Las Vegas.

Isn't it beautiful?
If you've never seen a rack before, I have to tell you, Helios is massive. This is not a normal rack, okay? It's a double-wide design based on the OCP Open Rack spec, developed with Meta, and weighs nearly 7,000 pounds.
It took a little effort to get it here. But we wanted to show you what's really powering all this AI behind the scenes. It's actually heavier than two compact cars.
Helios's design is the result of close collaboration with our key customers, chosen to optimize maintainability, manufacturability, and reliability for next-generation AI data centers.
Let me show you a bit more detail. The heart of Helios is the compute tray. Let's take a closer look at what one of those trays looks like.

I probably can't lift this compute tray, so it has to slide out of the rack. Let me describe it briefly. Each Helios compute tray contains four MI455 GPUs, paired with next-generation EPYC "Venice" CPUs and Pensando networking chips. All of this is liquid-cooled to maximize performance.
The heart of Helios is our next-generation Instinct GPU. You've seen me hold a lot of chips over my career, but today I can tell you, I'm genuinely excited to show this one.
Let me show you the MI455X for the first time.
MI455 is the most advanced chip we've ever made. It's big. It has 320 billion transistors, 70% more than MI355.
It contains 12 compute and I/O Chiplets at 2nm and 3nm, and 432 GB of ultra-fast HBM4 memory, all connected via our next-generation 3D chip stacking technology. We put four of these chips into the compute tray above.
Powering these GPUs is our next-generation EPYC CPU, codenamed Venice.
Venice extends our leadership across every key dimension in the data center: higher performance, better power efficiency, and lower total cost of ownership (TCO).
Let me show you Venice for the first time.
I have to say, it's another beautiful chip.
I really do love our chips. I can confirm that. Venice is built on 2nm process technology, with up to 256 of our latest high-performance Zen 6 cores.
The key is, we designed Venice to be the best AI CPU. We doubled the memory and GPU bandwidth compared to the previous generation. So, even at rack scale, Venice can feed the MI455 at full speed. The real magic is co-engineering. We bring all the components together with our 800G Ethernet Pensando Volcano and Salina networking chips, delivering ultra-high bandwidth and ultra-low latency. This enables thousands of Helios racks to scale within a data center.
To give you a sense of that scale, this means each Helios rack has over 18,000 CDNA 5 GPU compute units and over 4,600 Zen 6 CPU cores, delivering up to 2.9 Exaflops of performance.
Each rack also includes 31 TB of HBM4 memory, 260 TB/s of scale-up bandwidth, and 43 TB/s of aggregate scale-out bandwidth, moving data at incredible speeds. In short, the numbers are staggering.
When we launch Helios later this year—and I'm happy to say Helios is on track for later this year—we expect it to set a new bar for AI performance. To put that performance in perspective, just over six months ago, we launched MI355, delivering 3x higher inference throughput than the previous generation.
And now with MI455, we're taking that growth curve even further, delivering up to 10x performance gains across a broad range of models and workloads.
This is disruptive.
MI455 lets developers build larger models, more powerful agents, and more powerful applications.
And no company is pushing faster or further in these areas than OpenAI. To talk about where AI is going and our collaboration, I'm thrilled to welcome OpenAI President and Co-founder Greg Brockman to the stage.

Lisa Su: Greg, great to have you. Thanks for coming. OpenAI really kicked this all off with ChatGPT a few years ago, and the progress you've made is incredible. We're super excited about the deep collaboration. Can you paint a picture of where things are today? What are you seeing? How are we working together?
Greg Brockman: First, great to be here. Thanks for having me. ChatGPT really was kind of an "overnight success" story, but it was seven years in the making. Back when we founded OpenAI in 2015, we had a vision that deep learning could lead to AGI, to powerful systems that could benefit all of humanity. We wanted to help make that happen, to democratize it and bring it to the world. We spent a long time just grinding away, year after year, benchmarks looking better and better. But the first time we had something so useful that a lot of people in the world wanted to use it, that was ChatGPT. We were blown away by the creativity people showed in using our models in their daily lives.
Out of curiosity, how many of you are ChatGPT users?
Lisa Su: I see basically everyone's hand up.
Greg Brockman: I'm glad to hear that. But more importantly, how many of you have had an experience where AI was critical for your life or a loved one's life? Whether in healthcare, caring for a newborn, or other aspects of life.
For me, that's the metric we want to optimize. Watching that number grow is what made 2025 truly different.
We really went from a simple text box—you ask a question, get an answer—to people really using it for very personal, very important things in their lives. That shows up in personalized healthcare and more, but also in enterprises. We really started bringing in models like Codex to transform software engineering. I think this year we'll really see enterprise agents take off. We see scientific discovery starting to truly accelerate. Whether it's developing novel mathematical proofs—we saw that for the first time a few months ago, and it's continuing. This really goes across every area of human knowledge work, anywhere there's human intelligence to leverage, you can amplify it. We now have an assistant, a tool, an advisor that can amplify what people want to do.
Lisa Su: I completely agree, Greg. I think we've seen the scope of how we use this technology accelerate enormously. I'd say every time I see you, you tell me you need more compute.